The AI-Beats-Doctors Study Didn't Measure ER Medicine
Jeff Whatcott · May 8, 2026
A retrospective text-only experiment ran on AI’s home court. The headlines treated it like a clinical trial.

A new paper came out in Science this week. The research was fine, but headlines and hot takes about it highlight the prevalence of muddled thinking about AI. Brodeur and colleagues at Harvard, Beth Israel Deaconess, and Stanford reported that OpenAI’s o1 model outperformed two attending emergency room physicians at producing differential diagnoses on 76 cases from a Boston ER. The Guardian: “AI outperforms doctors in Harvard trial of emergency triage diagnoses.” NPR: “An AI model beat ER doctors at diagnosing patients.”
The Brodeur findings are landing into a frame that predated them. Two weeks earlier, at WIRED Health in London on April 16, Reid Hoffman told the audience that “if as a doctor, you’re not using one or more frontier models as a second opinion, my belief is you’re bordering on committing malpractice.” These AI systems, he said, are “bringing superpowers that no human being has.”
The paper is being read through Hoffman’s prior, not generating it.
Some headlines and confident commentary push a clear conclusion: “AI is ready, doctors who refuse it are dangerous, and the standard of care should change now.” Careful coverage pushes back, but the bold framing travels faster. That conclusion is wrong, and the reason it’s wrong is less about whether AI is good or bad at clinical reasoning and more about what the experiment measured.
The Brodeur ER experiment was not what most readers think it was. It was a retrospective analysis of 76 de-identified cases represented in text. Two attending physicians sat at desks, looked at text records pulled from past patient charts, and wrote differential diagnoses. The AI did the same. Two other physicians scored the lists, blinded to which were human and which were machine. That was the experiment. Nobody handed doctors laptops with GPT and watched them work a Tuesday-night shift in the ER. Nobody compared real-time clinical outcomes. Nobody studied a single live patient encounter.
Once you see the design clearly, the mainstream media narratives fall apart. The experiment tested how well physicians produce differential diagnoses from historical text records, while sitting at a desk, with no other demands on their attention. That is the AI’s native environment. It is a thin slice of what makes a physician a physician.
Look at what was missing from the test. There was no patient sitting in front of the physician. The way they breathed, the color of their skin, their affect, the way they held their abdomen, the way they hesitated before answering a different question. The family in the hallway looking worried and adding color commentary on the situation. None of that was in the experiment. The three other patients on the board, the EMS handoff, the page about labs from bed twelve, the nurse saying this one feels wrong to me, the fatigue, the unsplit attention. None of that was present either. The physicians performed an isolated written task on sterile text the AI processes natively. They were doing a tiny piece of their job in a foreign medium while the AI was on home turf.
The paper itself acknowledges this, but only narrowly. The authors note that “our study addresses only text-based performance” and that clinical practice “is awash with nontext inputs.” They frame this as a multimodal limitation: no images, no audio. The deeper limitation is harder to see from inside the paper. The test wasn’t merely missing modalities. It was missing the situated practice that makes physicians physicians. Senior author Adam Rodman gestured at this in his NPR interview, conceding that the result probably wouldn’t hold for “someone who’d spent a month in the hospital.” That’s an admission that case complexity past a certain envelope breaks the comparison. The point generalizes further than he took it. The comparison was already broken at zero complexity, because the experiment had already removed everything physicians do that doesn’t fit on a screen.
This is not a critique of the researchers. The question being studied is useful and important. The paper is honest, the methods are clear, the limitations are stated. The problem is the read: the gap between what the experiment could measure and what the headlines claimed it had shown.
Even within the experiment’s own frame, the results were less clean than the coverage suggested.
There are six experiments in the paper. The ER second-opinion task is one of them. The other five include findings that almost no outlet reported.
Experiment 3 measured the highest-stakes function in the entire study: identifying the cannot-miss diagnoses, the conditions doctors must not overlook because the patient dies if they do. On that task, o1’s performance was statistically indistinguishable from GPT-4, attending physicians, and residents. The model was no better at the safety-critical work than the people it was supposedly outpacing. This appears in the paper. It did not appear in NPR, The Guardian, or the Harvard press release.
Experiment 5 used a set of landmark diagnostic cases never publicly released, the gold-standard test for memorization-resistant evaluation. On those cases, o1’s advantage over physicians was not statistically significant. The p-values ran 0.055 to 0.076. The paper reports this honestly. The coverage skipped it.
In Experiment 4, physicians using GPT-4 as a decision-support tool scored 41% on a management reasoning test. GPT-4 alone scored 42%. The physician contribution to the AI-augmented score was zero. Either physicians were deferring to the model and adding nothing, or the model produced outputs so directive that human processing didn’t help. Either reading complicates the “AI as collaborative tool” narrative the senior authors gravitated to in their interviews. Only Ewen Harrison, editor of NEJM AI, raised this in expert commentary at Spain’s Science Media Centre.
The pattern is clear. Significant results became headlines. Null results disappeared. The Harvard institutional press release accurately quoted Manrai’s appropriate caution about deployment, but its body text selected only the statistically significant positive results. Several mainstream outlets called the ER component a “Harvard trial.” It was not a trial. The paper itself uses the word trial once, to describe the prospective work that has not yet been done. A 76-case retrospective second-opinion analysis at one academic medical center is not a trial. The vocabulary slipped, and once it slipped, the framing slipped with it.
Independent peer-reviewed evidence also runs the other way. Seventeen days before Brodeur, Arya Rao and colleagues published in JAMA Network Open after testing twenty-one AI models at each step of the diagnostic process. Their finding: AI reasoning is “brittle precisely where uncertainty and nuance matter most.” Their conclusion: LLMs are not yet ready for clinical decisions. Same week, same domain, opposite verdict. That paper got a fraction of the coverage Brodeur received.
This kind of slippage isn’t unique to this paper. It is the predictable pattern of how high-status results travel.
The people repeating these takes are not foolish. Hoffman is a serious thinker. The journalists are competent. Plenty of smart people have already concluded that AI is going to transform healthcare in eighteen months and are talking about it online.
What’s at work isn’t stupidity. It is confirmation bias amplified by the size of the prize.
When the consequences of a technology are large enough, and the consequences in healthcare AI are very large, there’s a strong gravitational pull toward reading every new result as confirming the trajectory you already believe in. The trajectory is AI changes everything, fast. When a new research result arrives, the reader’s mind fills in the gaps. The gaps fill in toward the prior belief.
The failure mode could be described as the “single-axis read problem.” The technical case looks complete to people who only see the AI technology. What gets under-weighted is everything that isn’t a model capability. Regulatory frameworks. Malpractice law. Hospital workflow integration. The EHR’s actual structure. Accountability requirements. Physicians’ situated awareness. The half-dozen nontext signals every encounter contains. The hard work of figuring out who signs the chart when something goes wrong. None of these are technical problems. All of them have to be solved before the headline can ever become a clinical reality.
The bordering-on-malpractice claim is, I think, a sincere expression of where Hoffman’s confidence resides. He’s a venture investor with stakes in AI health companies. That’s public information, not a hidden conflict, and I’m not suggesting he’s being dishonest. I am suggesting that when you build companies on a thesis, the thesis becomes a lens, and the lens is not optional. Everyone who reads through a thesis-centered lens does this. The work of the careful read is to notice when the lens is doing more work than the data is.
At Seampoint we have specific names for what’s missing in these takes. The most useful one is the difference between capacity and authority.
Capacity is what the AI can do. Capacity has been rising fast in medicine, and the Brodeur paper is a serious contribution to that evidence. The model is good at producing differential diagnoses from text. That is real, replicable, and it matters.
Authority is whether the AI should own the work, whether the seam between human and machine should move. Authority is governed by four constraints, and they don’t shift just because capacity shifted.
The first is consequence. How bad is it when the system gets the answer wrong? In medicine the answer is sometimes catastrophic. The second is verification cost. How hard is it to check the AI’s output? Sometimes cheap, often expensive, occasionally impossible without doing the work yourself. The third is accountability. When something fails, who answers to the patient, the family, the regulator? AI cannot be sued, fired, or imprisoned. The fourth is physical reality. Does the work require a human body in a room with another human body? Listening to lungs, feeling for an enlarged liver, reading a face, none of it moves to text.
The Brodeur experiment tested only part of one of these: verification cost, in degraded form, with the physician’s environment stripped out. It said nothing about the other three. In medicine all four are stringent and structurally unchanged by a benchmark result.

This is why the right read of the paper isn’t the boundary between humans and AI models should move. It’s that capacity rose at a specific seam, and the seam should be redesigned to use that capacity, with the human still owning consequence, accountability, and physical work. The Seampoint framework calls this the amplification of work. AI extends what a physician does, but the physician still signs the chart. The opposite move, replacement, requires authority to have moved, and authority has not moved (and should not move) in this case.
What would AI amplification look like? It is an emergency physician glancing at an AI-generated differential diagnosis as a backstop check before discharging a patient, with the official diagnosis on the chart still hers. It is a hospital running a passive AI scan over the EHR overnight to surface patterns a tired team might have missed, with a named clinician owning every flag. It is a primary-care physician using AI to draft the post-visit note from an AI-generated transcript that was recorded in real time so the physician could keep eye contact with the patient during the visit. The model is producing differentials, surfacing patterns, drafting notes. None of these moves authority from doctor to AI. All of them require structural adjustment of the workflow, and a named qualified human still owns the outcome.
We have data on this. Seampoint published a state-level analysis this month covering 1.6 million Utah workers across 679 occupations and 20 named employers. The analysis is built entirely from public information: BLS occupational data, public headcount profiles, and ONET task classifications run against the four governance constraints. We mapped public workforce composition against task-level governance scores. Healthcare came out the way the Seampoint framework predicts. Across three Utah health systems with very different business models, Intermountain Health, the University of Utah hospitals and clinics, and Revere Health, the share of clinical work that must stay human came in between nine and ten percent. The share AI can take over directly came in at ten to fifteen percent. The share AI can amplify came in between fifty and sixty percent. These are estimates from public data, not internal audits, but the stays-human floor holds across organizational types because it tracks the work, not the employer. The Brodeur paper does not move that floor. It might increase confidence in a slice of the amplify category, specifically differential support and second opinions. It does not move clinical work into the replace category, because the four authority constraints didn’t move.
Anthropic’s own production data points the same direction. Their Learning Curves report, released in March, shows that experienced AI users, people who have been using Claude regularly for six months or more, delegate less and iterate more than new users. They use AI as a thinking partner rather than as a substitute. They get measurably better outcomes by working with the model instead of handing off work to it. The empirical pattern in deployment, over time, runs opposite to the trajectory the bordering-on-malpractice framing assumes. Skilled users push the seam closer to human-AI collaboration, not further toward autonomous AI.
The proper conclusion from the Brodeur paper is the one the authors themselves drew. AI systems have eclipsed most text-based benchmarks of clinical reasoning. That is genuinely a milestone. It should demonstrate the urgent need for prospective trials of AI-physician collaboration in real clinical environments, with real patients, real hospitals, real workflows. Until those trials are run, we don’t know what we have, or whether it is safe to proceed beyond the status quo.
A real trial would look different from what was done here. It would put working physicians in their actual environment, with actual patients, with the AI integrated into the workflow they use, and measure not differential-list quality but downstream consequences.
Consider a specific trial deployment design our Seampoint framework could support. A hospital deploys AI as a backstop at the admission decision point, governed by what Seampoint calls the Decision-First Protocol. The admitting physician works the case, examines the patient, talks to the family, and logs a differential diagnosis with a disposition plan before seeing any AI output. Only then does the AI see the same EHR context the physician saw and return three candidate diagnoses with brief reasoning for each. The physician reviews the list. If the AI surfaces something worth considering, she decides whether to revise her diagnosis or hold the original. If not, she moves on. The admit, discharge, and imaging decisions stay with the physician. Both the initial diagnosis and the final diagnosis are logged, alongside the AI’s output and the eventual ground truth.
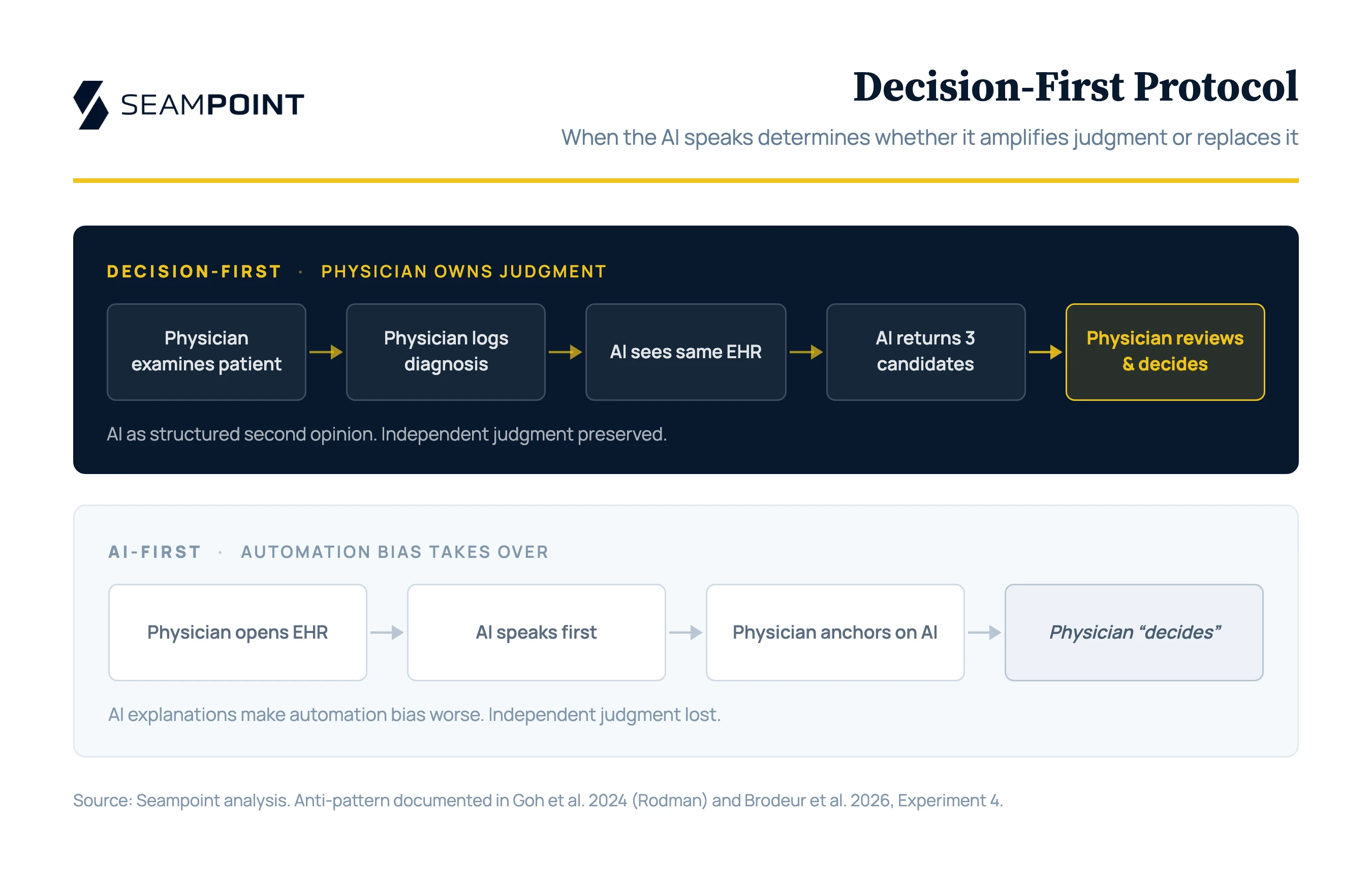
The sequence matters here. Decision-First exists because automation bias is real and well-documented, and because AI explanations actively make it worse: when the model offers plausible-sounding reasoning, humans accept its conclusions at higher rates regardless of whether that reasoning is correct. Rodman himself documented this pattern in 2024. Physicians using GPT-4 didn’t outperform GPT-4 alone, and post-hoc analysis of the chat logs revealed that doctors anchored on their initial diagnoses and ignored the model when it disagreed. Brodeur’s Experiment 4, two years later, reproduces the same finding. The pattern persists. Requiring the physician to commit before the AI speaks preserves independent judgment as the primary signal and reduces the AI to a structured second opinion rather than an anchor. It also generates the empirical record that holds both parties accountable. Every case yields a clean comparison. Where the physician was right and the AI was wrong. Where the AI surfaced something the physician missed. Where both got it right. Where both got it wrong. And the most diagnostic measurement of all: where the physician changed her diagnosis correctly after seeing the AI, versus where she changed it incorrectly under AI influence. That last delta is the empirical question that determines whether amplification works.
The trial deployment described above sits cleanly in the amplify category not replacement. Verification is cheap because the physician spends seconds reviewing a short list. Accountability is named because the admitting physician already owns the decision. Consequence is absorbed by a human who is already accountable for the outcome. Physical reality isn’t implicated, because no AI action touches the patient. The four authority constraints are satisfied by the surrounding human structure. Capacity is what the model brings.
A study of this trial deployment is empirically tractable. Cluster-randomized by physician or by shift, run across one or two academic sites for twelve to eighteen months, with success measured on three axes.
On patient outcomes, the candidate metrics include 30-day return-to-ED visits and 7-day mortality as proxies for missed diagnoses, time from arrival to definitive diagnosis, and imaging utilization measured both ways so the study catches AI suggestions that drive inappropriate workups. The most important measurement is cannot-miss diagnosis identification rate, validated by independent chart review. That’s the safety-critical metric Brodeur tested, and the one where o1 was not statistically better than physicians.
On practitioner satisfaction, the candidate metrics include self-reported cognitive load, interruption burden, validated burnout scales like the Maslach Burnout Inventory, and trust calibration tracked over time. The behavioral signal that matters most is voluntary continued use after the study window closes. A tool that improves patient outcomes by exhausting the clinicians who use it is not a sustainable deployment, and it will be abandoned the moment the research grant ends.
On financial impact, the candidate metrics include length of stay, 30-day readmission rate, diagnostic test ordering patterns, imaging spend, physician productivity measured by patients seen per shift, and lagged malpractice claim frequency where institutional data access permits it. Net cost change is calculated after the AI deployment itself is accounted for, including infrastructure, integration, and ongoing oversight.
A successful trial deployment looks like this. Missed-diagnosis rate decreases without inappropriate testing increasing. Practitioner satisfaction holds or improves and use continues voluntarily. Financial impact lands net favorable through fewer readmissions and shorter stays, even if imaging shifts modestly in either direction. A failed deployment looks like the opposite. Alert fatigue, increased testing without offsetting reductions, no movement on the safety metrics that matter, and physicians turning the system off the moment they have permission to do so.
That is the kind of study that would tell us whether the Brodeur capability translates into clinical benefit. None of it has been done. Until it is, we don’t know what we have.
When the consequences are this large, the right move is to slow down and get it right. The path forward is clear, but requires real methodical work and careful measurement. This work is what fills the gap between buzzy headlines and the safe diffusion of AI into the real economy.
If you run a hospital system, the question this paper invites is not “should we replace something with AI.” It is “where in our existing workflows is verification cheap, accountability already named, and consequence absorbed by a human who is already accountable?” Those are the seams where amplification deployments are ready to pilot now, because the four authority constraints are already satisfied by the surrounding human structure. Differential support inside an established physician’s workflow. EHR scanning with a physician owner for every flag. Documentation drafts a clinician edits and signs. Start there. Earn the trust, build the verification habits, and find out what the technology actually does inside your specific workflow before extending it.
Hoffman’s second-opinion framing was closer to right than the bordering-on-malpractice claim it sat beside. AI as a structured second opinion, delivered after the physician has committed her own diagnosis and logged against ground truth for accountability, is what amplification under Decision-First looks like. It is the deployment pattern the Brodeur paper actually supports. The looseness was in treating “second opinion” as a phrase that describes any AI consultation a physician might run, when in fact the sequencing determines whether the consultation helps the patient or anchors the physician toward an AI error. The same two words describe a deployment that improves outcomes and one that erodes judgment. The protocol around the words is the difference.
The Brodeur paper is good science. The careful read is that capacity at a specific seam moved meaningfully, the seam should be redesigned to use it, and the physician still signs the chart. Anyone telling you the headline is the finding hasn’t read the methods.
More to read

Refactoring Agents
What building agentic AI systems teaches about the overlap between software architecture and workforce design—and why the AI employee metaphor fails.

When AI Fear Goes Underground
When fear of AI stays unspoken, adoption stalls and pilots fail. Leaders can steady the organization with one reversible step: an AI practice group and a sentinel who keeps people facing the work together.

Why Companies Are Deploying AI Agents Backwards
AI agents keep arriving before the requirements that justify them. Runtime governance can contain the damage, but it can't replace the upstream decisions buyers skipped.
Where does AI belong in your processes?
Let us map the AI opportunities in your organization today.
Start a conversation