What Anthropic's Deployment Data Reveals
Jeff Whatcott · March 16, 2026

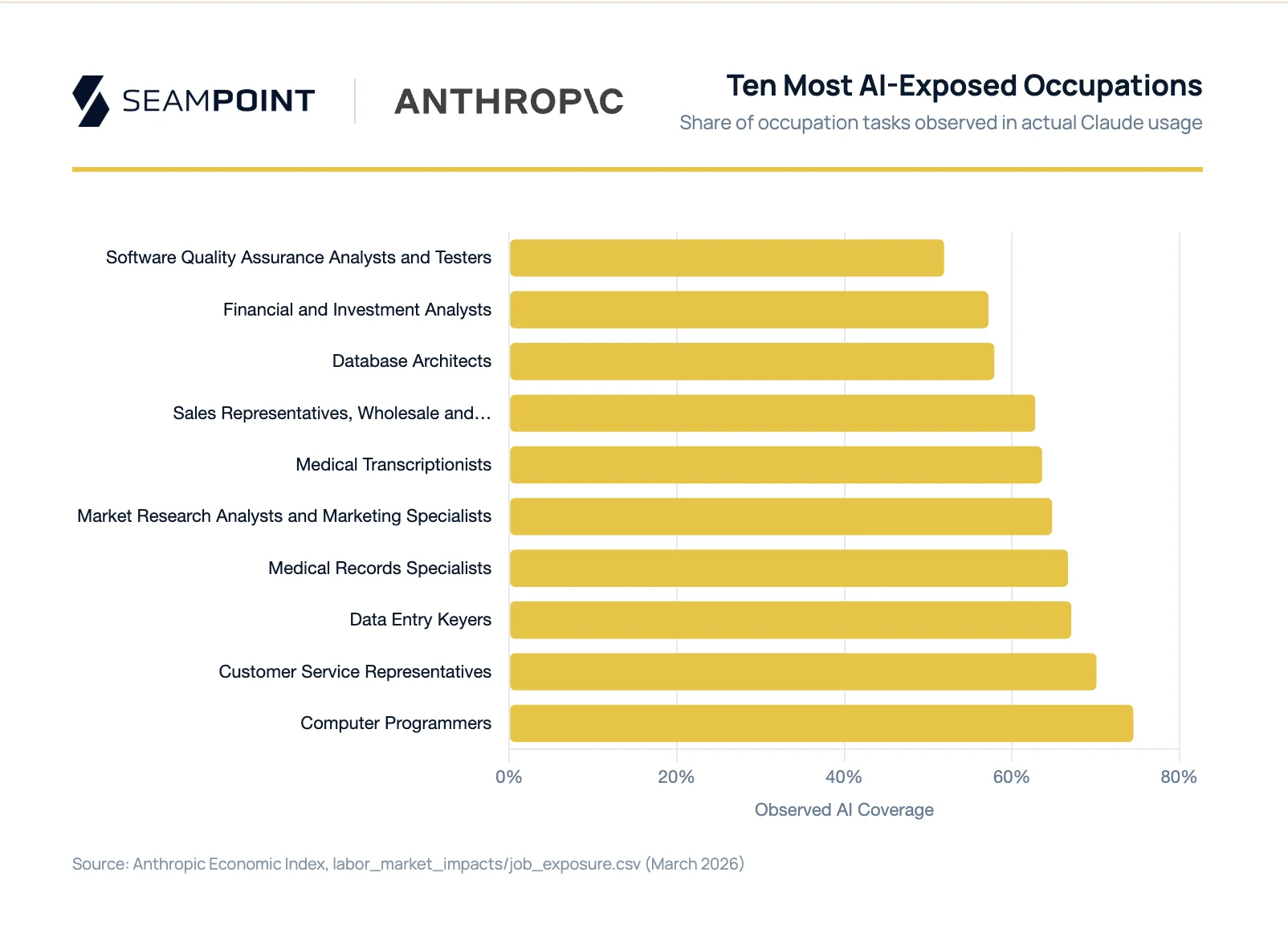
The AI forecasts circulating in boardrooms are wrong in the same direction. Capability assessments, which measure what percentage of tasks an AI model could theoretically handle, consistently overshoot what organizations actually deploy. Anthropic published data on March 5 that makes this visible for the first time at scale. Rather than modeling what Claude could do, they measured what Claude is doing: actual usage patterns across 756 occupations. In Computer & Mathematical occupations, the most AI-capable group in the economy, language models can theoretically speed up 94% of tasks. Observed usage in practice runs at 33%.
That 61-point gap is the number everyone will quote. The more useful question is why the gap has the shape it does.
Earlier this year we published The Distillation of Work, a framework for understanding which organizational tasks are actually ready to hand off to AI, and which governance barriers (accountability structures, verification requirements, consequence of error, physical environment) are doing the blocking. Both approaches operate at the O*NET task level and aggregate to the occupation weighted by time spent, which makes direct comparison meaningful. The methods differ at the task level: Anthropic scores each task as covered or not based on observed Claude usage; our framework scores governance constraints on a continuous scale. When we applied that framework to their 756 occupations, the structure of their gap became legible.
The most practically important distinction is one Anthropic’s data makes visible but their paper doesn’t name: the difference between core work and coordination work.
Core work is the specialized activity that defines a role: clinical diagnosis for a physician, investment judgment for a financial analyst, legal strategy for an attorney. The decisions that most visibly define these roles carry high governance weight: the consequences of error are serious, verification is difficult, and accountability structures require human judgment in the loop. Coordination work is the documentation, reporting, scheduling, and communication overhead that exists in every role regardless of the field. Physicians spend roughly 40% of their time on clinical decisions. The rest is notes, referrals, prior authorizations, messages to patients. Litigation lawyers have to meet with and send emails to their clients, other firms, and even officers of the court in addition to preparing briefs and arguing cases. All jobs have coordination overhead and coordination work is largely accessible to AI today: consequences are lower, verification is easier, and the tasks are digitally native.
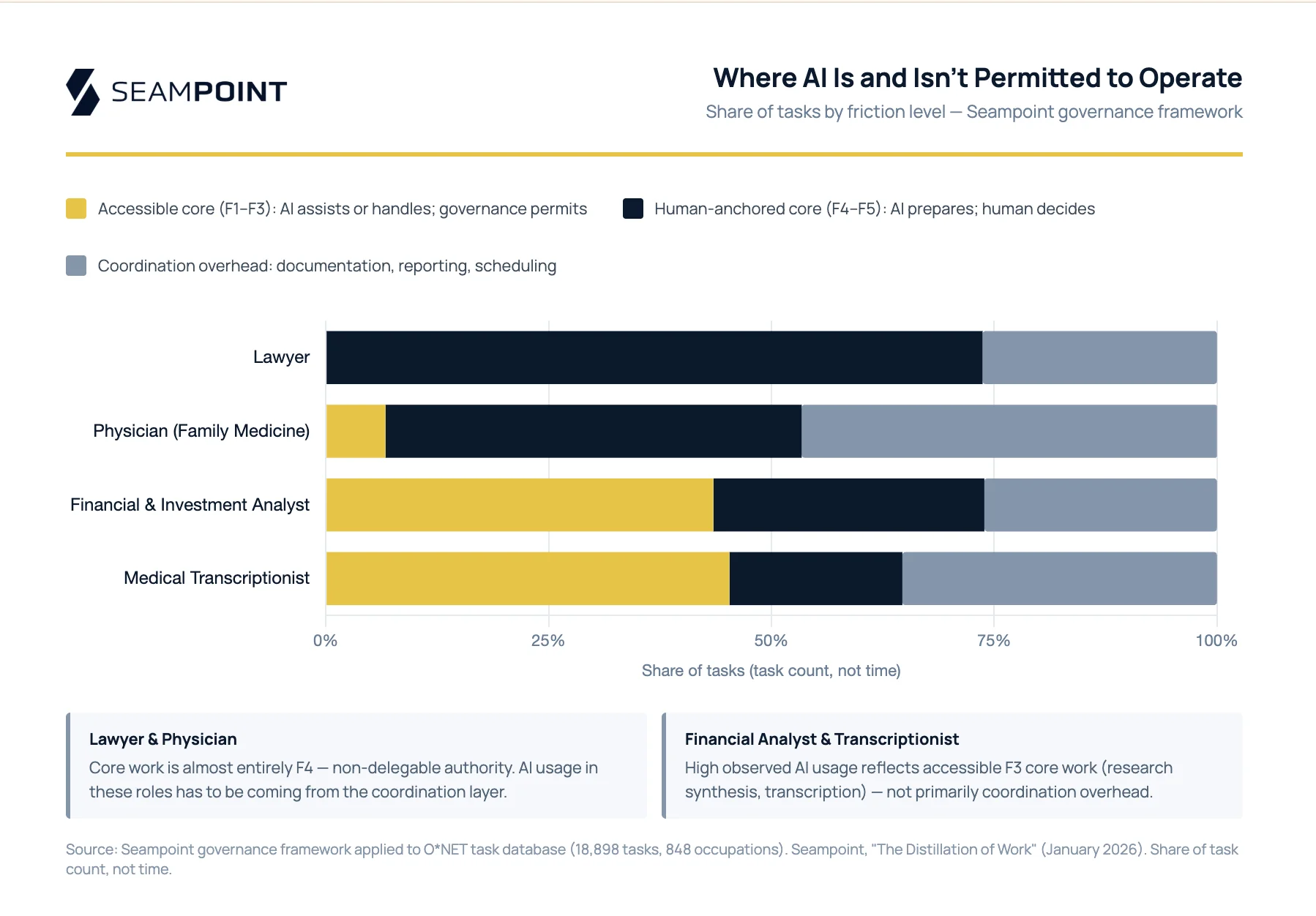
This distinction explains what looks like a paradox in Anthropic’s data. Medical transcriptionists show 64% observed AI usage and financial analysts 57%, far above what you’d expect if AI were making clinical decisions or investment calls. The source of that usage is occupation-specific. Financial analysts carry 44% of their tasks at Guided in our framework (expert verification required, but governance permits the task): research synthesis, scenario modeling, data extraction, all work where AI assists and a human validates. Coordination overhead adds another 26%. Medical transcriptionists tell a similar story: converting physician dictation into structured records is their core job, and it scores Guided throughout. In both cases, high observed coverage reflects accessible core work, not coordination work overhead. Physicians are the counterpoint: clinical decisions score Assisted, where AI prepares but accountability cannot transfer, so when AI usage shows up in physician workflows, it has to be coming from the coordination layer.
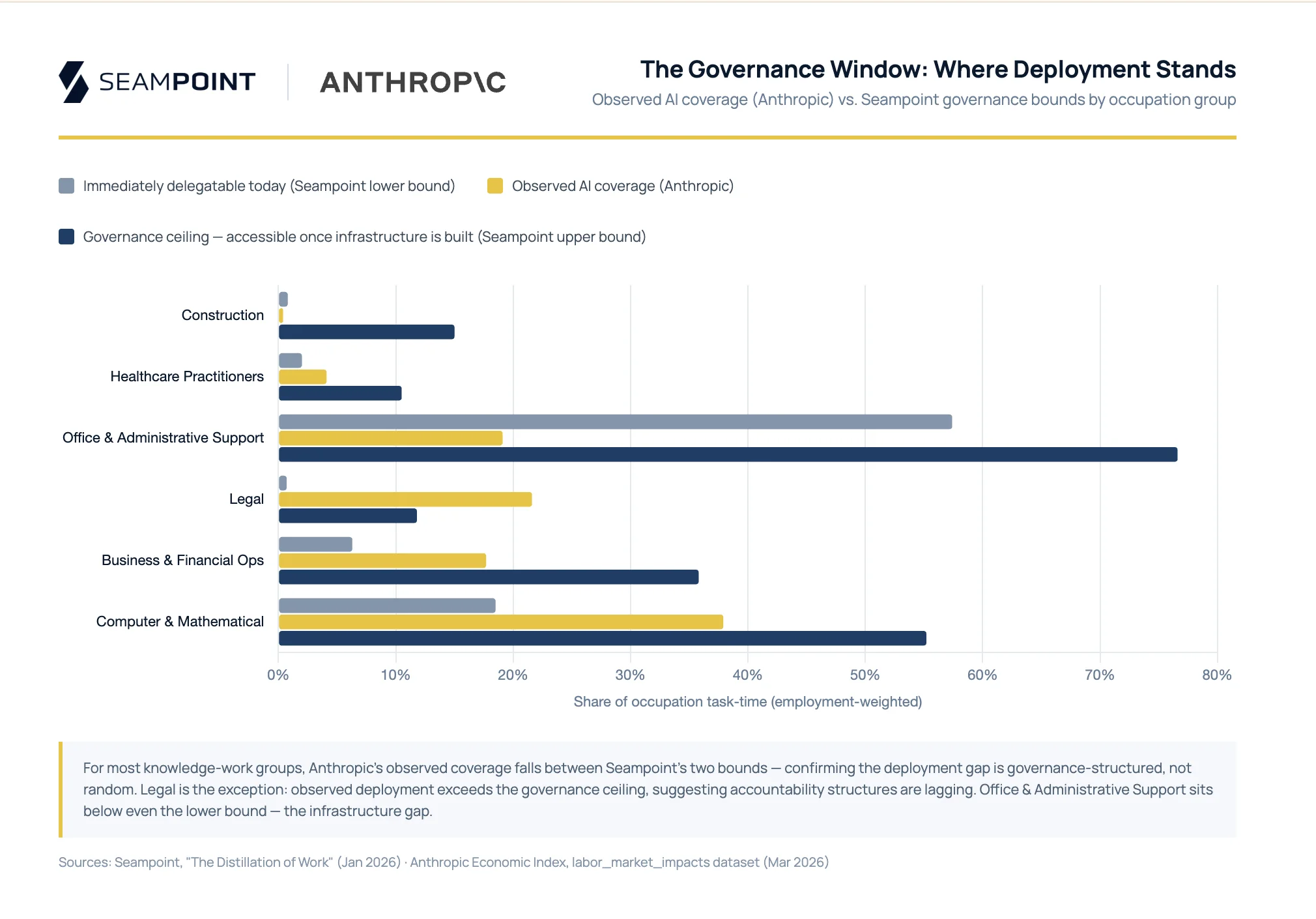
At the occupation level, Anthropic’s observed coverage falls between two bounds our Seampoint framework produces: the share of tasks that clear every governance hurdle today, and the share that would clear once organizations build the right verification and accountability infrastructure. For Computer & Mathematical occupations, our immediate-delegation estimate is 18% and our governance-constrained upper estimate is 52%. Anthropic measured 33%, landing between the two. The same pattern holds across most knowledge-work groups. Computer programmers at 74.5% observed against our estimate of 67%, customer service representatives at 70.1% against 71%, database architects at 57.9% against 56%, all near-perfect matches. Data entry keyers are the exception: every task is immediately delegatable, but only 67% are being handled by AI. That gap is workflow integration that hasn’t been built.
The gap isn’t random. Deployment is bounded below by tasks organizations can hand off to AI today, and bounded above by tasks they could hand off if they built the workflows to handle them responsibly. The distance between those bounds is an organizational capability gap, not a model capability gap.
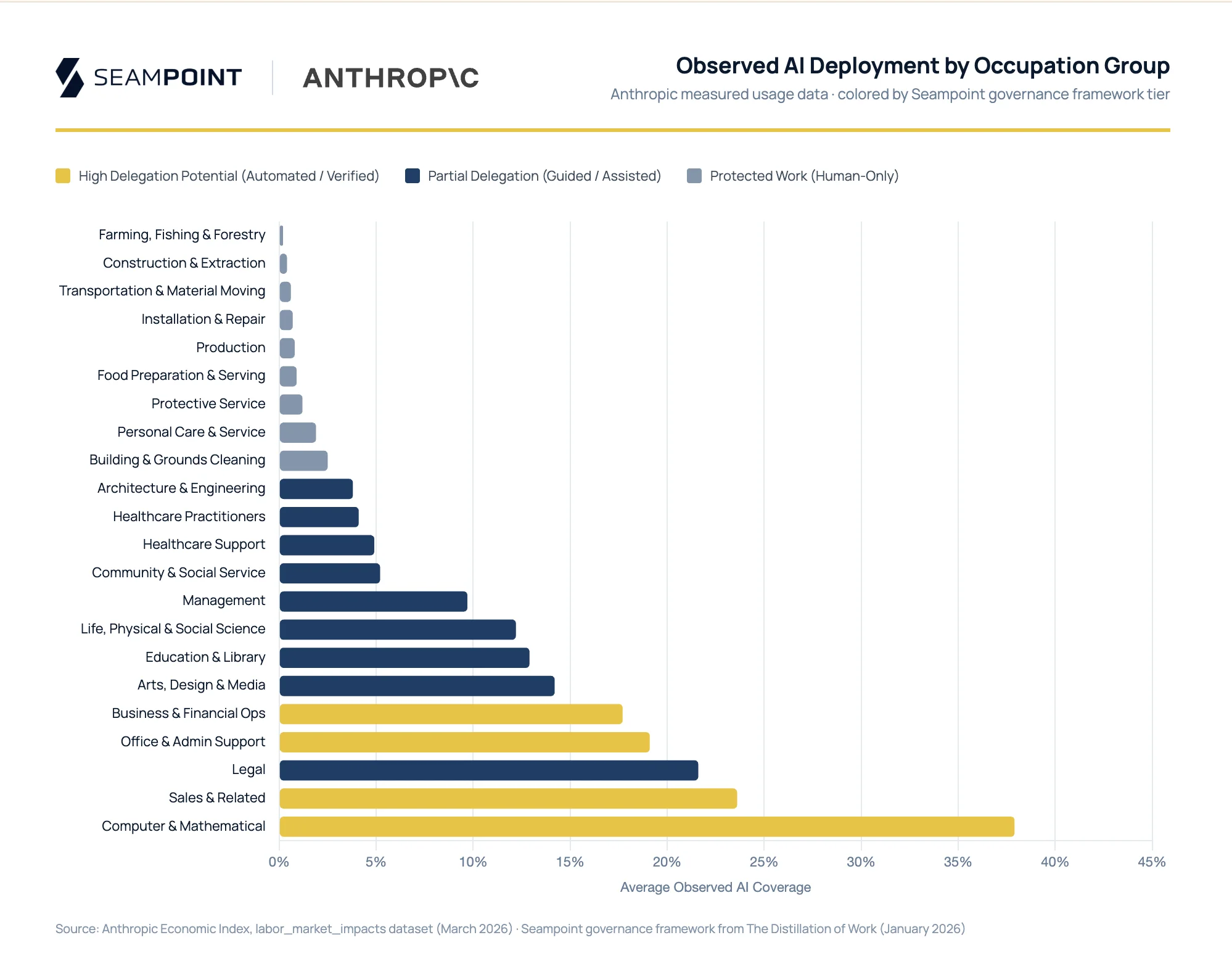
Physical work in unstructured environments sits below even the lower bound. Observed coverage for agriculture, construction, installation and repair, food service, and grounds maintenance runs at zero or near-zero across all of Anthropic’s data. A custom equipment welder working in an unstructured industrial environment isn’t being displaced, not because AI can’t draft a work order, but because unstructured physical environments create capital and safety barriers no language model improvement addresses. This work remains human because it has to be.
The accountability constraint shows up in ways Anthropic’s data reflects but their paper doesn’t explain. Prior research rates authorizing drug refills as fully AI-capable, with a language model theoretically cutting the time in half. Anthropic has never observed Claude performing it. The AI can prepare, but a human must authorize, and that constraint isn’t a capability gap. It is regulatory, ethical, and structural.
That Anthropic finds no prescription refill usage in Claude reflects the regulatory environment: it’s not allowed in most states. Utah has been running an AI regulatory sandbox allowing an AI chatbot to evaluate and recommend prescription renewals gated by physician consultation, with controlled substances excluded. Red teaming researchers recently demonstrated that the implementation was vulnerable to prompt injection: fabricated directives produced clinical summaries recommending controlled substance dosages, transmitted to physicians before consultations. The exploit worked by degrading human judgment rather than bypassing it: a physician reviewing an AI briefing ten minutes before a video call is not making a fresh assessment. The intent was sound; hardening against prompt injection can put this pilot back on track.
Legal is the notable exception, the one group where observed deployment (22%) exceeds our governance-constrained estimate of roughly 10%. Part of the explanation is coordination work: research memos, correspondence, and drafting carry lighter governance weight than courtroom representation, and Anthropic’s measurement captures all of it. Part of it is that deployment is genuinely outrunning accountability structures. Attorneys have filed briefs citing AI-hallucinated cases. The ABA has issued supervision guidance the profession is still learning to apply. 22% observed coverage tells you how much legal work Claude is touching. It tells you nothing about the quality of human review on the other end.
Workforce dynamics
Anthropic’s report also covers workforce dynamics. Workers in the most exposed occupations skew older, female, more educated, and higher-paid ($32.69 per hour versus $22.23 for unexposed workers). The deployment opportunity concentrates among workers better resourced to handle transitions. Hiring of workers aged 22–25 into exposed occupations appears to have slowed by roughly 14% since ChatGPT’s release. Existing workers adapt; entry pathways narrow for roles defined primarily by tasks AI now handles.
BLS employment projections through 2034 track observed AI coverage, not theoretical exposure. Jobs with higher observed coverage are projected to grow less, while theoretical exposure alone shows no such correlation. Deployment patterns predict labor market shifts, not theoretical capability.
The organizational capability gap
The largest gap in Anthropic’s data is Office and Administrative Support: 90% theoretical exposure, 19% observed, our governance-constrained estimate at 71%. Knowledge workers spend 57–60% of their time on coordination work, and the coordination tasks in Office & Admin are highly accessible: low-consequence, easily verified, and digitally native. What’s missing isn’t capability or governance clearance. It’s the workflow integration, accountability structure, and workforce fluency that organizations haven’t built yet.
Leaders who plan from theoretical exposure will overshoot. Leaders who plan from current observed usage will undershoot. The core/coordination distinction tells you where to start: coordination work is accessible now, and deploying there builds the verification habits and institutional knowledge that make core-work deployment tractable later.
The distance between Anthropic’s measurements and what organizations have actually built isn’t a model improvement problem. It’s an organizational capability problem. Unlike model improvements, that’s something leaders can actually control.
The Distillation of Work is available on our site. Anthropic’s report, “Labor market impacts of AI: A new measure and early evidence,” was published March 5, 2026. Their data is available on HuggingFace.
More to read

A Tale of Three AI Cars
Three self-driving philosophies from Subaru, Waymo, and Tesla reveal what happens when AI gets confused—and why operating protocols matter more.

The AI-Beats-Doctors Study Didn't Measure ER Medicine
A retrospective text-only experiment ran on AI's home court. The headlines treated it like a clinical trial.

8 Hours with AI and College Football Bias
A BYU fan tests five AI systems on college football rankings. The experiment reveals how bias shapes AI outputs—even when objectivity is the goal.
Where does AI belong in your processes?
Let us map the AI opportunities in your organization today.
Start a conversation